
 Un document PDF numérisé est un fichier numérique contenant une image d'un document physique numérisé à l'aide d'un scanner. Le scanner capture le texte et les images sur le document physique et les convertit au format numérique, puis les enregistre sous forme de fichier PDF. Les documents PDF numérisés peuvent contenir tout type de matériel imprimé, y compris des livres, des rapports, des factures et d'autres documents. Contrairement aux documents PDF modifiables, les PDF numérisés ne sont généralement pas consultables ou modifiables sans l'aide d'un logiciel de reconnaissance optique de caractères (OCR).
Un document PDF numérisé est un fichier numérique contenant une image d'un document physique numérisé à l'aide d'un scanner. Le scanner capture le texte et les images sur le document physique et les convertit au format numérique, puis les enregistre sous forme de fichier PDF. Les documents PDF numérisés peuvent contenir tout type de matériel imprimé, y compris des livres, des rapports, des factures et d'autres documents. Contrairement aux documents PDF modifiables, les PDF numérisés ne sont généralement pas consultables ou modifiables sans l'aide d'un logiciel de reconnaissance optique de caractères (OCR).
Avantages du fichier PDF consultable
Certains avantages des documents PDF interrogeables sont les suivants :
- Augmentation de la productivité: La recherche d'informations spécifiques dans un document PDF interrogeable est beaucoup plus rapide et plus efficace que la numérisation manuelle de pages de texte.
- Accessibilité améliorée : Les lecteurs d'écran peuvent lire à haute voix des documents PDF interrogeables, ce qui les rend accessibles aux personnes malvoyantes.
- Collaboration simplifiée : La collaboration sur des documents est rendue plus accessible lorsque le texte est consultable. Les membres de l'équipe peuvent rapidement trouver et extraire les informations nécessaires pour terminer leur travail.
- Espace de stockage réduit : Les documents PDF consultables peuvent être compressés sans perdre leur capacité de recherche, ce qui leur permet d'occuper moins d'espace de stockage.
La technologie OCR (Optical Character Recognition) permet de générer des documents PDF consultables. Il s'agit d'un outil logiciel qui numérise de gros volumes de documents, convertit les enregistrements physiques en fichiers électroniques consultables et améliore la précision de la saisie des données. Le logiciel OCR peut être autonome, intégré dans un scanner ou intégré à un logiciel de gestion de documents. Cependant, la précision de l'OCR peut être affectée par la qualité du document, le type de police et la langue. Il est donc crucial de choisir un logiciel OCR de haute qualité et d'optimiser le processus de numérisation pour obtenir les meilleurs résultats.
Qu'est-ce que l'OCR ?
L'OCR, connue sous le nom de reconnaissance optique de caractères, est une technologie qui permet la reconnaissance de texte imprimé ou manuscrit dans une image, puis convertit ce texte en texte lisible par machine.
Les quatre principaux types d'OCR sont :
- La reconnaissance optique de caractères, ou OCR, est une technologie utilisée pour reconnaître le texte imprimé dans une image et le convertir en texte lisible par machine. La technologie OCR est largement utilisée pour numériser des documents imprimés, tels que des livres, des magazines et des documents juridiques.
- OWR, ou Optical Word Recognition, est une technologie similaire à l'OCR mais spécifiquement conçue pour reconnaître des mots entiers dans une image. Cette technologie est couramment utilisée dans les applications de reconnaissance de l'écriture manuscrite, où il est essentiel de reconnaître des mots complets plutôt que des caractères individuels.
- OMR, ou Optical Mark Recognition, est une technologie utilisée pour reconnaître des marques spécifiques faites sur un formulaire papier, telles que des cases à cocher ou des bulles. La technologie OMR est couramment utilisée dans les tests standardisés, les enquêtes et d'autres applications où les données doivent être collectées à partir de formulaires papier.
- ICR, ou Intelligent Character Recognition, est une technologie qui reconnaît le texte manuscrit dans une image. La technologie ICR est plus complexe que l'OCR ou l'OWR car elle nécessite l'identification de caractères individuels et la mise en correspondance de ces caractères avec une base de données de caractères connus.
Lorsque l'on compare ces technologies, il est essentiel de considérer leurs forces et leurs faiblesses.
- L'OCR est très précis pour reconnaître le texte imprimé, mais peut rencontrer des difficultés avec l'écriture manuscrite ou un texte mal imprimé.
- OWR est conçu explicitement pour la reconnaissance de l'écriture manuscrite et peut être plus précis pour cette application.
- L'OMR est très précis pour reconnaître des marques spécifiques sur un formulaire papier, mais ne peut pas reconnaître le texte.
- L'ICR est le plus complexe et peut gérer une plus large gamme d'écritures manuscrites, mais il peut nécessiter une formation approfondie et peut ne pas être suffisamment précis pour certaines applications.
En fin de compte, le choix de la technologie dépend de l'application spécifique et du type de texte ou de symboles qui doivent être reconnus.
Comparaison des logiciels OCR populaires disponibles en 2023
Comme indiqué précédemment, la technologie OCR est principalement utilisée pour extraire automatiquement du texte à partir de fichiers PDF et d'images numérisés. Il existe de nombreux outils disponibles à cet effet, et ici, nous fournirons une brève introduction au logiciel OCR le plus populaire en 2023 :
- AcePDF
- Tesseract OCR
- ABBYY FineReader
- Google Cloud Vision
- Extrait d'Amazon
Tous ces outils sont livrés avec un ensemble de fonctionnalités différent et nous avons évalué leurs forces et leurs faiblesses pour vous permettre de choisir facilement le meilleur outil OCR qui répond le mieux à vos besoins. Dans notre comparaison, nous avons constaté qu'AcePDF est facile à utiliser et offre une gamme de fonctionnalités liées à l'OCR, ce qui fera de la tâche de reconnaissance de texte PDF une évidence pour vous. Il n'a aucun problème avec les documents bien numérisés et a même bien reconnu le texte dans le document capturé par smartphone.
OCR un document PDF numérisé
La plupart des fichiers PDF flottant sur le Web contiennent du texte incorporé, et de nombreux programmes de bureau et mobiles populaires et des ensembles de logiciels de numérisation intègrent la technologie OCR. Néanmoins, il existe encore des cas où le document ou l'image source contient des quantités importantes de texte non intégré qui ne peut pas être extrait mécaniquement.
Dans ce scénario, l'OCR peut être effectuée automatiquement à l'aide d'un pipeline de logiciels gratuits et open source. Ceci est particulièrement utile lorsque vous travaillez avec un vaste corpus de documents dont l'intégralité du texte doit être indexé ou lors de l'ingestion de documents ou d'images dans une application Web qui doit extraire du texte.
Voici un guide étape par étape pour l'OCR d'un document PDF numérisé :
- Choisissez un logiciel OCR : Plusieurs logiciels OCR sont disponibles sur le marché. Vous pouvez choisir n'importe lequel d'entre eux, comme AcePDF ou tout autre que vous êtes à l'aise d'utiliser.
- Ouvrez le document PDF numérisé : Ouvrez le document PDF que vous souhaitez ROC dans votre logiciel ROC.
- Sélectionnez la fonctionnalité OCR : Démarrez le processus OCR en sélectionnant l'outil OCR dans votre logiciel OCR. L'emplacement de l'outil OCR peut varier selon le logiciel que vous utilisez.
- Sélectionnez les paramètres OCR : Choisissez la langue du document que vous souhaitez ROC. Vous pouvez également avoir la possibilité de sélectionner le niveau de précision de l'OCR, ce qui peut affecter le temps de traitement et la qualité de sortie.
- Démarrez le processus d'OCR : Une fois que vous avez sélectionné les paramètres OCR, démarrez le processus OCR en cliquant sur le bouton "OCR". Cela peut prendre un certain temps, selon la taille du document et le niveau de précision que vous avez sélectionné.
- Examinez la sortie OCR : Une fois le processus OCR terminé, examinez la sortie OCR pour vous assurer que le texte est correctement reconnu. Vérifiez s'il y a des erreurs, des fautes d'orthographe ou des problèmes de formatage.
- Enregistrez la sortie OCR : Une fois satisfait de la sortie OCR, enregistrez le document avec la sortie OCR en tant que nouveau fichier PDF. Vous pouvez également enregistrer le document dans d'autres formats, tels que Microsoft Word ou texte brut.
- Modifiez la sortie OCR (facultatif) : S'il y a des erreurs dans la sortie OCR, vous pouvez modifier le texte dans votre logiciel OCR ou exporter le texte vers un traitement de texte pour apporter les modifications nécessaires.
En suivant ces étapes, vous pouvez ROC un document PDF numérisé et le convertir en un format numérique consultable et modifiable.
Meilleur logiciel OCR
Si vous débutez dans la reconnaissance optique de caractères (OCR), AcePDF est le seul outil dont vous avez besoin. L'exécution d'OCR pour rendre les PDF numérisés consultables n'est qu'une des nombreuses fonctionnalités avec lesquelles AcePDF peut vous aider. En tant qu'éditeur et convertisseur PDF robuste, il est livré avec de nombreux outils uniques qui vous aideront à gérer vos flux de travail PDF et, en fin de compte, vous aideront à être plus productif au travail. Certaines de ces fonctionnalités étonnantes sont les suivantes :
- Les annotations et les fonctionnalités de balisage abondent dans cet éditeur PDF, qui permet l'annotation de documents PDF avec des surlignages, des soulignements, des légendes, des flèches et bien plus encore.
- Convertissez sans effort des fichiers PDF en formats modifiables tels que Word, Excel ou PowerPoint à l'aide du convertisseur intégré de cet éditeur de PDF.
- Fonction d'en-têtes et de pieds de page pour améliorer la lisibilité du document PDF dans son ensemble.
Problèmes courants d'OCR et solutions
La technologie OCR peut être bénéfique pour reconnaître le texte dans les images, mais plusieurs problèmes courants peuvent survenir au cours du processus OCR. Voici quelques-uns des problèmes d'OCR les plus courants et comment AcePDF peut aider à les résoudre :
- Mauvaise qualité d'image : Si l'image en cours d'OCR est de mauvaise qualité, le logiciel OCR peut ne pas reconnaître le texte avec précision. AcePDF utilise des algorithmes de traitement d'image avancés pour améliorer la qualité de l'image et améliorer la précision de l'OCR.
- Langues mixtes : Si l'image contient du texte en plusieurs langues, le logiciel OCR peut avoir des difficultés à reconnaître le texte. AcePDF prend en charge l'OCR dans plus de 20 langues, ce qui facilite la reconnaissance précise de textes multilingues.
- Dispositions complexes : Le logiciel OCR peut avoir des difficultés à reconnaître le texte avec précision si l'image contient des mises en page complexes, telles que plusieurs colonnes ou tableaux. Les algorithmes OCR avancés d'AcePDF sont conçus pour identifier avec précision le texte dans des mises en page complexes, ce qui facilite l'extraction des données de ces documents.
- Documents volumineux : Si l'image en cours d'OCR est volumineuse, le processus d'OCR peut prendre beaucoup de temps. AcePDF utilise des algorithmes de traitement parallèle avancés pour OCR rapidement et efficacement des documents volumineux.
Rendre le fichier PDF numérisé consultable
Un PDF consultable est un document qui permet à l'utilisateur de rechercher un texte ou des mots-clés spécifiques dans le document.
AcePDF peut être utilisé pour rendre les fichiers PDF numérisés consultables ; Voici comment:
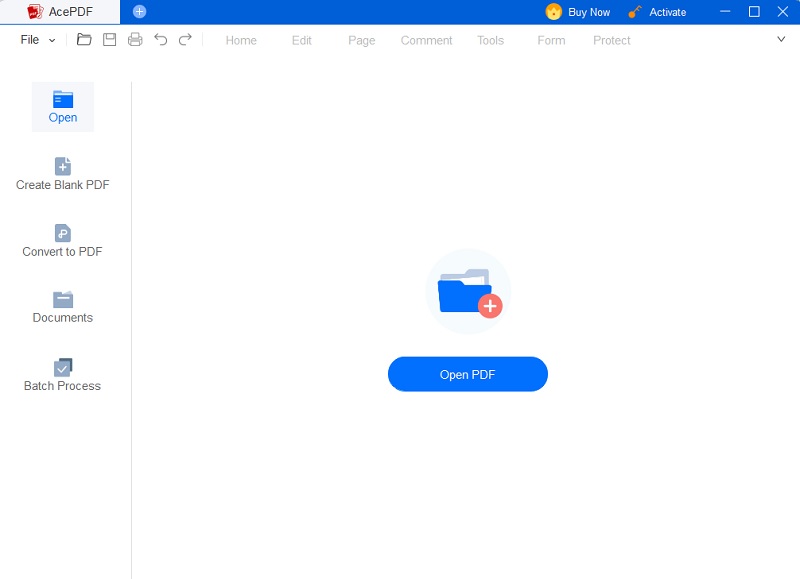
Étape 1 Installez AcePDF et lancez-le
Lancement AcePDF et chargez le fichier PDF numérisé que vous souhaitez rendre consultable. Une fois le document PDF numérisé ouvert dans AcePDF, allez dans le menu principal et choisissez l'outil OCR. Dans la plupart des cas, vous pouvez trouver la fonction OCR dans la section "Outils" située sur le côté gauche du programme.Essayez-le gratuitement
Étape 2 Choisissez la langue et les paramètres OCR dans la boîte de dialogue de l'outil OCR
Choisissez les options d'OCR telles que la plage de pages et le format de sortie. Choisissez la langue du document numérisé pour qu'elle corresponde à celle prise en charge par la reconnaissance optique de caractères (OCR) d'AcePDF.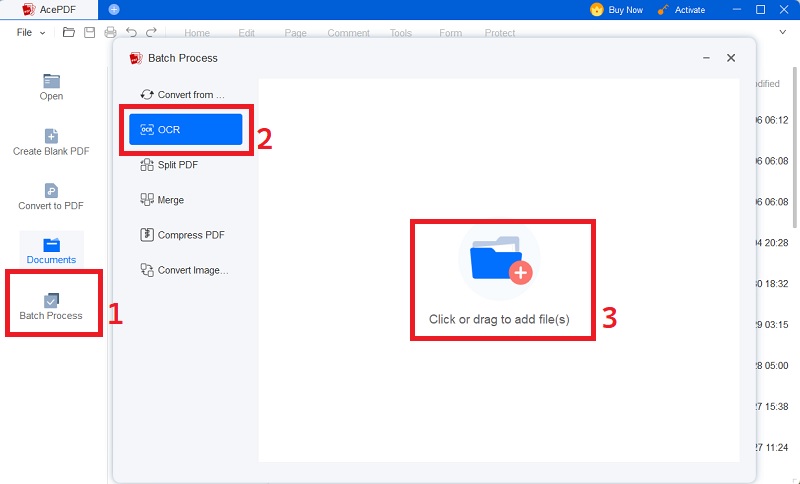
Étape 3 Commencer le processus d'OCR
Pour commencer le processus d'OCR, cliquez sur le bouton "OK". Après cela, AcePDF examinera le fichier et déterminera comment extraire le texte de l'image. Une fois l'OCR terminé, inspectez la sortie pour vous assurer que le texte a été correctement reconnu. Vérifiez qu'il est exempt de fautes de frappe, de fautes de grammaire et de mauvaise présentation. Vous pouvez corriger toute erreur dans le texte en le modifiant dans AcePDF.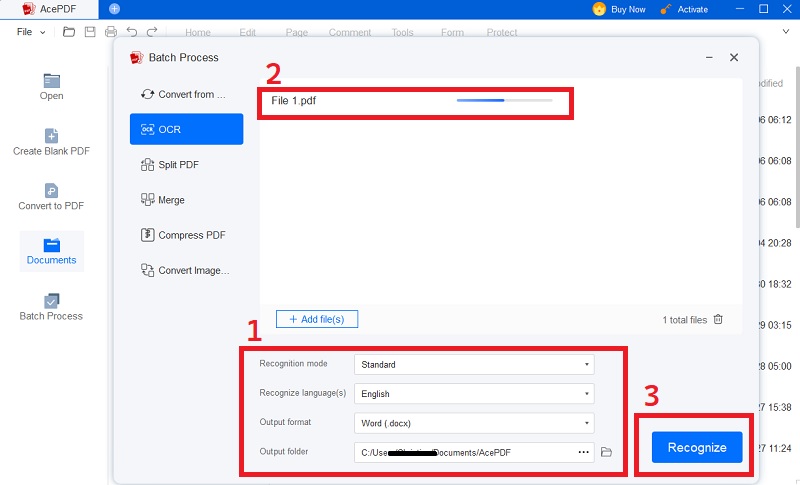
Étape 4 Enregistrer le fichier
Enregistrer le fichier PDF interrogeable Une fois que vous avez obtenu les résultats souhaités, enregistrez le document en tant que fichier PDF interrogeable.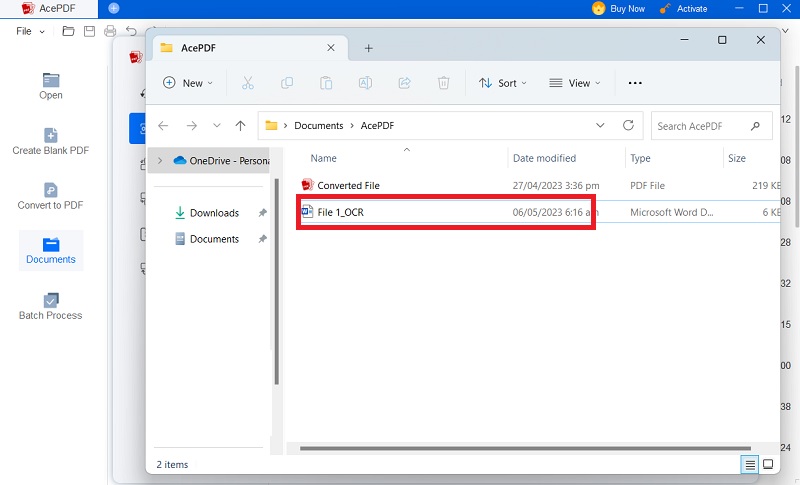
Conseils pour rechercher des PDF numérisés
Il ne serait pas faux de dire que le PDF est actuellement l'un des formats de document les plus couramment utilisés. Parfois, vous devrez peut-être exécuter la reconnaissance de texte pour rendre le contenu de cette page consultable et sélectionnable. Cependant, la recherche manuelle d'une phrase ou d'un mot spécifique dans un PDF contenant des centaines de pages peut s'avérer difficile. Si vous faites partie de ces milliers d'utilisateurs qui utilisent fréquemment des PDF, nous vous aiderons ici à savoir comment rechercher des documents PDF numérisés et discuterons de quelques conseils pour créer des PDF numérisés consultables.
Comment rechercher du texte dans un document PDF numérisé ?
Dans cette section, vous trouverez les étapes à suivre pour rechercher un PDF numérisé :
- Tout d'abord, vous devez convertir le PDF numérisé en un format modifiable, tel qu'un document Word. Pour cela, vous pouvez utiliser un convertisseur PDF tel que AcePDF.
- Téléchargez le document dans ce format texte modifiable, puis vous pourrez modifier, personnaliser les pages et changer la langue si vous le souhaitez.
- Dans la dernière étape, vous pouvez maintenant rechercher votre texte spécifique. Vous pouvez simplement appuyer sur les touches 'Ctrl + F' et entrer le mot ou la phrase que vous cherchez à rechercher dans la barre de recherche.
Meilleures pratiques pour rendre les documents PDF numérisés consultables
Après avoir expliqué comment rechercher du texte dans un document PDF numérisé, nous allons partager ici certaines des meilleures pratiques qui vous aideront à optimiser la possibilité de recherche et les avantages de l'utilisation de documents PDF.
- Assurez-vous toujours d'obtenir la bonne résolution lorsque vous numérisez des images au format PDF. Comme la qualité de l'OCR peut également souffrir d'une résolution de numérisation inférieure, il est recommandé de numériser à 300 dpi (points par pouce).
- Vous devriez opter pour les niveaux de gris plutôt que pour le noir et blanc, car cela vous aidera à conserver plus de détails. Si votre document contient des images ou des graphiques en couleur, vous devez vous assurer de le numériser en mode couleur.
- Tous les programmes OCR ne sont pas créés égaux, et la qualité de l'OCR pour rendre les PDF numérisés consultables dépendra des paramètres et des fonctionnalités offerts par le logiciel. Il est donc nécessaire d'obtenir un bon logiciel capable de fournir une meilleure qualité d'OCR.
- Une luminosité trop élevée ou trop faible peut affecter négativement la précision et la capacité de recherche des documents PDF. Par conséquent, une luminosité moyenne de 50 % serait une option sûre pour la plupart des numérisations.
- Habituellement, les scanners disposent de nombreux paramètres qui peuvent aider à améliorer la qualité de la numérisation et, en fin de compte, la possibilité de recherche. Par exemple, la « suppression de l'arrière-plan » et la « suppression des ombres sur les bords » peuvent améliorer la lisibilité des documents. Cependant, ils nuisent parfois à la précision de l'OCR. Donc, vous devriez exécuter quelques tests et regarder quels paramètres peuvent aider à rendre vos documents consultables.
Foire aux Questions
A. Tous les fichiers PDF ont-ils la même structure ?
- Absolument pas! Il existe de nombreuses façons de créer un PDF. Les PDF générés électroniquement et à partir de documents papier numérisés sont les deux types les plus courants que vous rencontrerez. Cela produit respectivement un PDF "natif" et des PDF numérisés. L'interactivité du PDF dépend de la manière dont le document a été préparé à l'origine.

B. Pouvez-vous expliquer le PDF natif ?
- Les PDF "natifs" sont développés numériquement à partir d'une autre source numérique. Un PDF natif est créé à partir d'un autre format numérique, tel que Microsoft Word ou Excel. Les fichiers PDF natifs contiennent une structure interne lisible et interprétable.
C. Comment puis-je savoir si j'ai un PDF consultable ?
- Pour savoir si votre fichier PDF est consultable, vous devez vous assurer que le fichier en question est basé sur du texte. Cela signifie qu'il doit contenir du texte réel. Pour vérifier si vous avez un fichier PDF interrogeable ou non, vous devez l'ouvrir et rechercher ou sélectionner du texte avec votre clavier ou votre souris. Si vous n'êtes pas en mesure de sélectionner ou de surligner du texte, cela signifie simplement que le PDF n'est pas consultable.
