
 La reconnaissance de texte PDF est un processus qui consiste à convertir des fichiers PDF numérisés ou basés sur des images. Il se transforme en documents texte modifiables et consultables. La reconnaissance de texte PDF change la donne pour les entreprises, les professionnels et les particuliers. Il est destiné aux utilisateurs qui traitent quotidiennement de gros volumes de fichiers PDF. Si vous traitez fréquemment des fichiers PDF contenant du texte numérisé ou basé sur des images, l'OCR PDF est une fonctionnalité indispensable. Il peut vous faire économiser d'innombrables heures de saisie manuelle fastidieuse de données et rendre votre flux de travail plus efficace. De plus, il peut vous aider à trouver rapidement et facilement des informations spécifiques en vous permettant de rechercher dans le texte de vos fichiers PDF. Cet article vous aidera à explorer les meilleurs outils de reconnaissance de texte PDF et comment ils peuvent vous être utiles. Alors, continuez à lire pour approfondir vos connaissances.
La reconnaissance de texte PDF est un processus qui consiste à convertir des fichiers PDF numérisés ou basés sur des images. Il se transforme en documents texte modifiables et consultables. La reconnaissance de texte PDF change la donne pour les entreprises, les professionnels et les particuliers. Il est destiné aux utilisateurs qui traitent quotidiennement de gros volumes de fichiers PDF. Si vous traitez fréquemment des fichiers PDF contenant du texte numérisé ou basé sur des images, l'OCR PDF est une fonctionnalité indispensable. Il peut vous faire économiser d'innombrables heures de saisie manuelle fastidieuse de données et rendre votre flux de travail plus efficace. De plus, il peut vous aider à trouver rapidement et facilement des informations spécifiques en vous permettant de rechercher dans le texte de vos fichiers PDF. Cet article vous aidera à explorer les meilleurs outils de reconnaissance de texte PDF et comment ils peuvent vous être utiles. Alors, continuez à lire pour approfondir vos connaissances.
Qu'est-ce que la reconnaissance de texte ?
La reconnaissance de texte est également connue sous le nom de reconnaissance optique de caractères (OCR). Cette fonction convertit le texte à base d'images en texte numérique modifiable et consultable. Ce processus implique un logiciel analysant l'image ou le document numérisé. Il identifie des mots ou des caractères pour recréer une représentation fidèle du texte original. OCR PDF est utilisé lorsque du texte doit être extrait d'images ou de documents PDF numérisés, tels que des reçus, des factures et des fichiers PDF. Dans le cas des fichiers PDF, la reconnaissance de texte vous permet de convertir des documents PDF non interrogeables en documents interrogeables en extrayant le texte de pages numérisées ou basées sur des images. S'il te plaît cliquez ici pour en savoir plus.
PDF consultable
Un PDF consultable est un document numérique dont le contenu textuel peut être recherché électroniquement, comme tout autre mot ou fichier texte. C'est parce que le texte a été reconnu et extrait à l'aide d'un logiciel OCR. Il convertit les images en fichiers modifiables et indexables pour une recherche et une organisation efficaces.
PDF non consultable
Les fichiers PDF non consultables sont créés en numérisant un document physique ou une image. Il est enregistré sous forme de fichier PDF sans aucune reconnaissance d'image. Cela signifie que le texte du document de fichier est essentiellement comme une image et ne peut pas être modifié ou recherché électroniquement.
Outils pour la reconnaissance de texte PDF
1. AcePDF
AcePDF Editor est un outil puissant qui offre l'OCR PDF comme l'une de ses nombreuses fonctionnalités. Ce programme est spécialement conçu pour les utilisateurs qui ont besoin d'éditer ou de modifier des fichiers PDF et qui souhaitent rechercher rapidement dans le texte de leurs documents. Les utilisateurs peuvent importer n'importe quel fichier PDF basé sur une image. Cette fonctionnalité permet aux utilisateurs de convertir plusieurs fichiers PDF simultanément. Vous pouvez même choisir la langue de votre fichier PDF pour vous assurer que la reconnaissance de texte est précise et efficace. Outre la reconnaissance de texte, AcePDF Editor propose également diverses options d'édition. Il aide à ajouter, supprimer et modifier du texte ou des images dans un fichier PDF. Il permet plusieurs changements de mise en forme. Cela inclut la modification de la taille ou du type de police et l'ajustement de l'espacement des paragraphes. L'outil reconnaîtra automatiquement le texte à l'aide de son extracteur de texte PDF. De plus, le programme prend en charge le traitement par lots. Enfin, il vous permet d'extraire ou d'exporter votre fichier avec différents formats tels que Word, PowerPoint, Excel et PDF. Suivez la procédure ci-dessous pour comprendre comment les atteindre.
Télécharger gratuitement
Étape 1 Téléchargez et lancez AcePDF
La première étape consiste à installer AcePDF. Pour ce faire, choisissez le bouton "Télécharger" qui correspond au système d'exploitation de votre ordinateur parmi l'option ci-dessus. Une fois que vous avez enregistré le programme d'installation, cliquez dessus et suivez les instructions de l'assistant de configuration pour une installation réussie. Vous pouvez ensuite vous familiariser avec ses fonctionnalités en explorant son interface image-texte.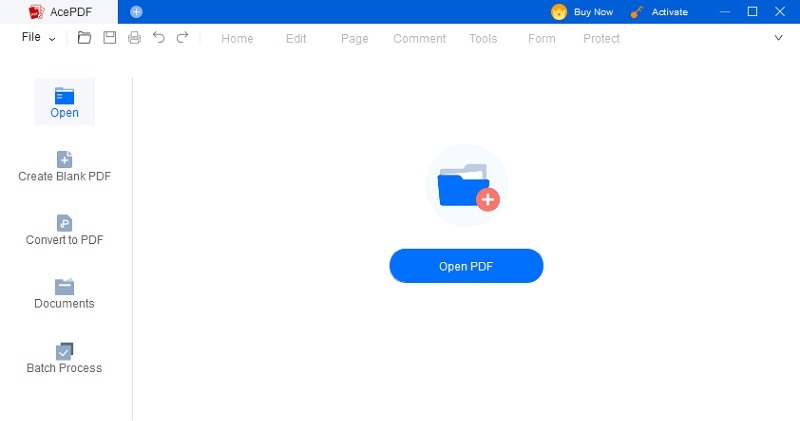
Étape 2 Importez votre fichier PDF basé sur une image
Pour accéder à votre fichier, cliquez sur l'icône "Ouvrir le dossier" au centre. Un menu de fichiers apparaîtra sur votre écran, où vous pourrez sélectionner le document souhaité. Une autre option consiste à utiliser le bouton "Ouvrir un fichier" situé sur le panneau de gauche de l'outil pour importer des fichiers. De plus, une icône "+" supplémentaire dans le coin supérieur gauche permet d'ajouter facilement des documents dans le logiciel PDF to text.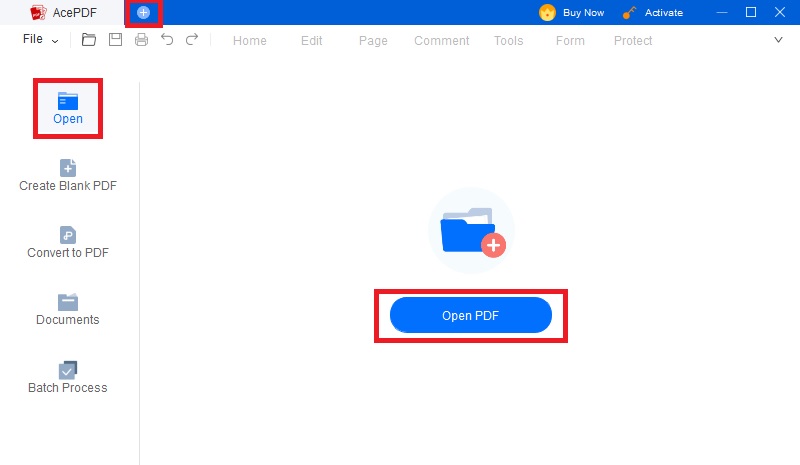
Étape 3 Convertir un PDF en texte à l'aide de l'OCR
Pour commencer, sélectionnez « Traitement par lots » sur le panneau de gauche de l'outil. » Ensuite, choisissez « OCR » parmi les options disponibles pour lancer la reconnaissance de mots PDF. Cliquez sur l'icône « + Ajouter des fichiers » pour importer des documents numérisés. Un PDF numérisé sera utilisé comme illustration pour ce guide particulier. Ensuite, procédez en spécifiant le mode de reconnaissance, la préférence de langue et les détails du dossier de sortie avant de sélectionner le format souhaité pour votre sortie. Enfin, cliquez sur le bouton "Reconnaître" pour commencer la reconnaissance de texte processus.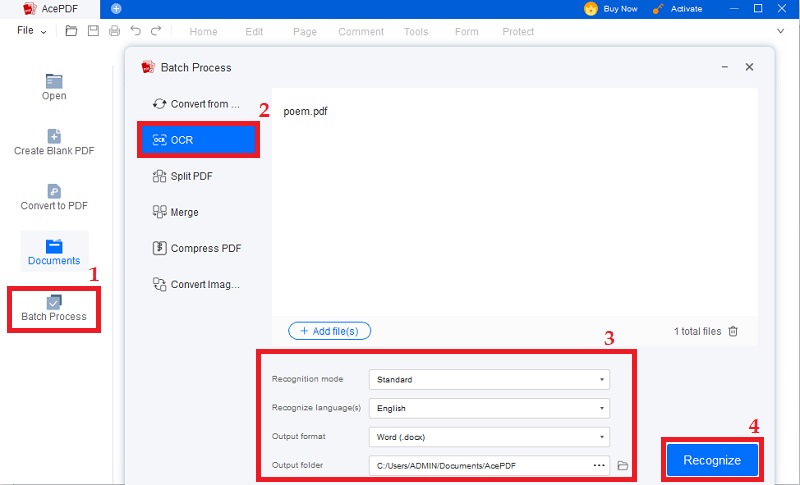
Étape 4 Localiser et vérifier le texte reconnu
Une fois le processus terminé, vous pouvez vérifier le texte reconnu en ouvrant le dossier de sortie. Accédez au répertoire désigné et recherchez votre document numérisé. Cliquez sur le bouton droit de la souris sur le fichier et choisissez "Ouvrir avec". Ensuite, sélectionnez un programme approprié parmi les choix disponibles pour ouvrir votre fichier. À ce stade, vous pouvez procéder à la modification de votre fichier comme vous le souhaitez.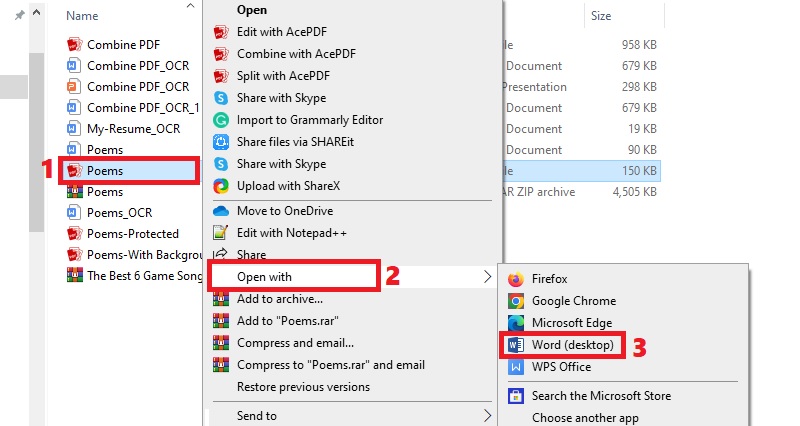
- L'outil peut convertir des fichiers numérisés en Word, PDF, Excel et PowerPoint.
- Il dispose d'une fonction de sécurité avancée qui offre le cryptage des fichiers et la signature électronique numérique.
- La version gratuite du programme n'offre qu'un ensemble limité de fonctionnalités à utiliser.
2. Adobe Acrobat Pro DC
Adobe Acrobat Pro DC est un autre logiciel OCR PDF fiable pour une reconnaissance de texte précise et efficace dans les fichiers PDF à base d'images. Sa version pro nécessite un abonnement qui coûte 19 $ par mois. Malgré son prix, il offre de nombreuses fonctionnalités, telles que la possibilité de créer, éditer et sécuriser des fichiers PDF. Sa fonction OCR est également très avancée. Vous pouvez même reconnaître du texte dans plusieurs langues, transformer des documents numérisés en PDF consultables et modifiables et conserver la mise en forme du document d'origine. De plus, sa fonction PDF to Text permet le traitement par lots, ce qui signifie que vous pouvez reconnaître du texte dans plusieurs fichiers simultanément. Il prend en charge divers formats de sortie tels que Word, Excel et PowerPoint. Vous pouvez utiliser ce logiciel si vous avez un volume élevé de documents numérisés qui doivent être convertis en texte modifiable et consultable qui peut valoir le prix.
- Il a la particularité de conserver la fonction de formatage d'origine.
- Il existe des fonctionnalités avancées telles que la reconnaissance de texte dans plusieurs langues.
- Son coût d'abonnement payant de 14.99 $ pourrait ne pas être réalisable pour tout le monde.
3. ABBY FineReader
ABBYY FineReader est un logiciel de reconnaissance de texte PDF idéal qui offre à la fois une facilité d'utilisation et des capacités avancées de reconnaissance de texte. Cet outil possède des fonctionnalités pour l'affichage, la recherche et l'impression de PDF. D'autre part, il dispose d'un éditeur OCR à des fins d'image en texte. Il est développé pour la conversion et la vérification avancées des documents numérisés. Il peut reconnaître du texte en anglais, allemand, français, espagnol et bien d'autres langues. De plus, l'outil peut reconnaître du texte dans des tableaux et d'autres formats de documents structurés. Les utilisateurs peuvent modifier le texte, les images et la mise en forme dans le document de sortie. La meilleure partie est que vous pouvez enregistrer et ouvrir le fichier converti dans Microsoft Word, Excel et d'autres formats de documents populaires.
- Il possède une interface simple qui convertit directement les documents en PDF, Word, Excel, etc.
- Il améliore la qualité de l'image avant la conversion avec des fonctionnalités telles que la résolution, la luminosité, le recadrage, etc.
- Le logiciel peut être coûteux pour les utilisateurs occasionnels et coûte 69 $ par an.
Conseils | Meilleures pratiques | Résoudre les problèmes courants
Conseils pour obtenir une reconnaissance de texte PDF précise et efficace
- Utilisez des analyses de haute qualité : Une entrée de qualité supérieure extraira efficacement le texte du PDF avec une meilleure sortie. Assurez-vous que vos scans sont en haute résolution et clairs.
- Choisissez un logiciel de reconnaissance de texte fiable : Sélectionnez un logiciel OCR adapté à vos besoins et capable de reconnaître du texte dans plusieurs langues si nécessaire.
- Vérifiez et corrigez les erreurs : Après la conversion OCR, vérifiez soigneusement le texte pour les erreurs ou les mots manquants, car parfois même le meilleur logiciel OCR peut faire des erreurs.

Meilleures pratiques pour optimiser la qualité des documents PDF numérisés
Pour optimiser la qualité des documents PDF numérisés, il est recommandé de suivre les meilleures pratiques lors de l'utilisation d'un service OCR hors ligne et en ligne. Vérifiez plus pour PDF numérisé vers Word.
- Il est essentiel de s'assurer que l'image numérisée a une résolution et une clarté élevées. Cela signifie que l'image doit être claire et nette, avec tous les détails visibles. Cela peut améliorer considérablement vos chances d'obtenir d'excellents résultats OCR PDF vers Word lorsque vous travaillez avec des documents numériques.
- Évitez d'utiliser des polices trop complexes ou stylisées dans le document d'origine. Il s'agit notamment d'éviter les conceptions complexes et les éléments décoratifs qui entravent la clarté et la lisibilité du texte lors de la numérisation. En simplifiant les choix de polices, vous pouvez augmenter vos chances de produire des numérisations de haute qualité facilement reconnaissables par la technologie OCR PDF vers Word.
- Minimisez la quantité d'arrière-plan et d'autres distractions dans les images numérisées. Assurez-vous que les documents sont bien formatés pendant le processus de numérisation. De plus, toutes les taches ou marques sur le document doivent être supprimées avant la numérisation afin de réduire les interférences avec le logiciel OCR premium ou gratuit. En prenant ces mesures, vous pouvez améliorer considérablement vos résultats d'OCR et vous assurer que vos documents numérisés sont exacts et fiables.

Comment résoudre les problèmes courants de reconnaissance de texte
Les problèmes courants de reconnaissance de texte dans les logiciels PDF OCR en ligne ou hors ligne peuvent inclure des erreurs de reconnaissance de caractères, un formatage manquant et correct et des difficultés à reconnaître du texte dans des tableaux ou d'autres documents structurés. Pour résoudre ces problèmes, essayez les techniques suivantes :
- Pour garantir la meilleure qualité de vos documents numérisés, il est recommandé d'effectuer une double vérification et d'évaluer leur clarté et leur résolution globales. Si des problèmes sont identifiés, nous vous suggérons de renumériser à une résolution plus élevée pour de meilleurs résultats. Trouvez le meilleur outil pour OCR PDF Online, comme AcePDF.
- Avant de commencer le processus PDF OCR Mac ou Windows, assurez-vous que les paramètres de langue de votre logiciel sont configurés pour reconnaître et interpréter avec précision la langue spécifique du texte converti. Le non-respect de cette consigne peut entraîner une sortie incorrecte ou des conversions incomplètes. Passez en revue cette étape cruciale avant de procéder à toute tâche de numérisation de documents.
- Après avoir terminé le processus de conversion OCR, il est essentiel d'examiner et de corriger manuellement tout problème de formatage pour garantir l'exactitude. Cela comprend l'examen des erreurs ou des incohérences qui ont pu se produire au cours du processus de numérisation et la réalisation des ajustements nécessaires en conséquence. La prise de ces mesures contribuera à améliorer la qualité et la lisibilité globales du document.

L'utilisation de la reconnaissance de texte PDF dans différents domaines
La reconnaissance de texte PDF s'est avérée utile dans divers domaines. Il est important de numériser des documents physiques et de les rendre consultables. Vous pouvez trouver l'utilisation de l'API OCR dans les cas d'utilisation réels suivants :
- Recherche académique: La reconnaissance de texte PDF peut parcourir rapidement de gros volumes de littérature et extraire des informations pertinentes pour faciliter l'analyse des données. Les instituts de recherche utilisent la reconnaissance de texte PDF pour convertir les articles et documents de recherche physiques au format numérique. Cela les rend plus facilement consultables pour référence future.
- Secteur financier : La reconnaissance de texte PDF est utile pour traiter et analyser les rapports sans ressaisir manuellement les données. Il est utile dans le secteur financier pour convertir les états financiers, les factures et les reçus au format numérique.
- Services juridiques: Les cabinets d'avocats utilisent le logiciel OCR PDF Mac ou Windows pour convertir des documents physiques. Il comprend la conversion des contrats juridiques et des dossiers au format numérique, ce qui facilite la recherche et l'organisation. Il facilite également l'analyse et l'examen plus rapides des documents pendant les procédures judiciaires.
